
Write Anywhere, Read Everywhere: Achieving True Data Interoperability Between Databricks and Snowflake
This blog will show you how to eliminate data silos between Databricks and Snowflake using Federation, enabling you to write from anywhere and read from everywhere under unified governance.

Update, July 23, 2025:
This Snowflake documentation explains catalog-linked databases, a new feature that enables Snowflake to directly connect to and interact with external Apache Iceberg™ REST catalogs
TLDR
Use Apache Iceberg + a shared catalog layer to make data readable across Databricks and Snowflake without copying files between platforms.
The core pattern is bidirectional federation: Databricks can query Snowflake-managed Iceberg tables, and Snowflake can query Unity Catalog–managed Iceberg tables.
Unity Catalog acts as the governance and interoperability layer, exposing Iceberg metadata through the REST catalog standard.
This approach reduces data silos, duplicate pipelines, and fragmented access control, while keeping storage open and engine-flexible.
Be explicit about current vs preview capabilities: cross-platform reads are available now; some write/sync experiences are still evolving.
Understanding the Foundation: Apache Iceberg and Catalogs
Before diving into the Federation solution, it's essential to understand the technology that enables seamless interoperability: Apache Iceberg.
What is Apache Iceberg?
Apache Iceberg is an open table format designed for large-scale data storage in data lakes. Think of it as a sophisticated "table of contents" for your data files in cloud storage. Unlike traditional file formats, Iceberg provides:
ACID transactions for data consistency
Time travel capabilities to query historical data
Schema evolution without breaking existing queries
Efficient query planning through rich metadata
Why Iceberg Needs a Catalog
Here's the imp point: Iceberg tables require a catalog to function. The catalog serves as the "phone book" that:
Tracks table locations in cloud storage
Manages metadata about schemas, partitions, and snapshots
Handles concurrent access from multiple engines
Provides governance and access control
The Iceberg REST Catalog Standard
The Iceberg REST Catalog is a standardized API that allows any Iceberg-compatible engine to interact with table metadata. This is crucial because it means:
Any engine (Databricks, Snowflake, Trino, etc.) can read the same tables
Unified governance through a single catalog interface
No vendor lock-in - your data remains accessible across platforms
Unity Catalog implements this Iceberg REST Catalog standard, making it the perfect bridge between different data platforms.
The Customer Challenge I See Often
We'll now explore how Federation can address another common interoperability challenge I frequently observe with customers. This involves scenarios where customers use both Snowflake and Databricks, desiring to write from both engines while making all data accessible to both.
In essence, the goal is to write from anywhere and read from everywhere.
The Real-World Problem
Organizations using both platforms consistently face these pain points:
Data trapped in silos: Teams can't easily access data created in the other platform
Complex data movement: Engineers spend time building pipelines just to move data between systems
Governance fragmentation: Security policies and compliance become nightmares to manage
Limited flexibility: Adding new analytics engines requires extensive integration work
The solution? Federation in both directions.
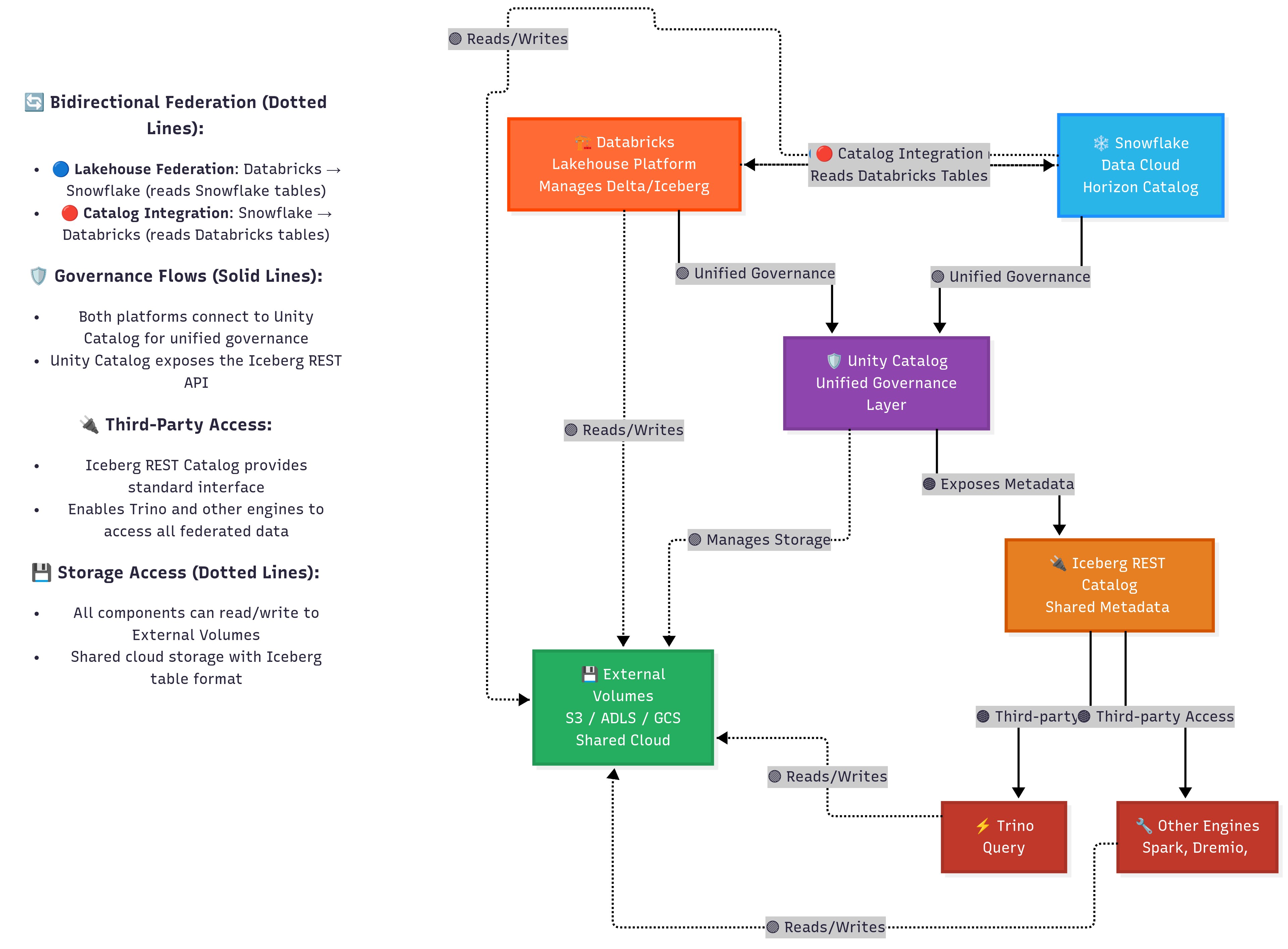
The Federation Solution: Unity Catalog as the Bridge
To achieve seamless interoperability, Federation can be employed in both directions:
From Databricks to Snowflake: Lakehouse Federation
Lakehouse Federation allows you to register a Snowflake Horizon catalog within Unity Catalog (UC). Once external locations are created for all Iceberg tables in your federated catalog, UC will know to access object storage to read those tables.
From Snowflake to Databricks: Catalog Integration
In the reverse direction, Snowflake offers a "catalog integration" that operates very similarly to Lakehouse Federation. Ultimately, this involves registering the Unity Catalog within Snowflake as an external catalog, enabling you to query these tables directly within Snowflake.
The Architecture's Key Advantage: Flexibility
A significant advantage of this architecture is its flexibility. For example, if you decide to utilize an open-source Iceberg engine, as previously discussed, UC already supports the Iceberg REST catalog. This allows you to connect, for instance, Trino to the Iceberg REST Catalog API for writing or reading to UC. Furthermore, all tables federated from the Snowflake Horizon Catalog are available in UC, meaning Trino could also read your Snowflake-managed Iceberg tables from Unity Catalog—all under unified governance.
The Complete Federation Architecture
The solution leverages bidirectional federation to create a seamless data ecosystem where any engine can access data from any other:
This architecture enables:
Databricks can access Snowflake-managed tables through Lakehouse Federation
Snowflake can access Databricks-managed tables through Catalog Integration
Third-party engines like Trino can access both through Unity Catalog's Iceberg REST API
Unified governance across all platforms and engines
Implementation Guide: Step-by-Step
Prerequisites
Before implementing the solution, ensure you have:
Databricks Unity Catalog enabled and configured
Snowflake account with appropriate privileges
Cloud storage access is configured for both platforms
Authentication credentials (service principal recommended)
Step 0: Enable External Data Access on Metastore
Create data assets
In your Databricks workspace, click Catalog
Click the gear icon at the top of the Catalog pane and select Metastore
On the Details tab, enable External data access
This setting allows external engines to access data in your metastore through the Unity Catalog REST APIs. It's disabled by default for security.
Step 1: Grant Access in Databricks
First, give Snowflake permission to access your Unity Catalog tables:
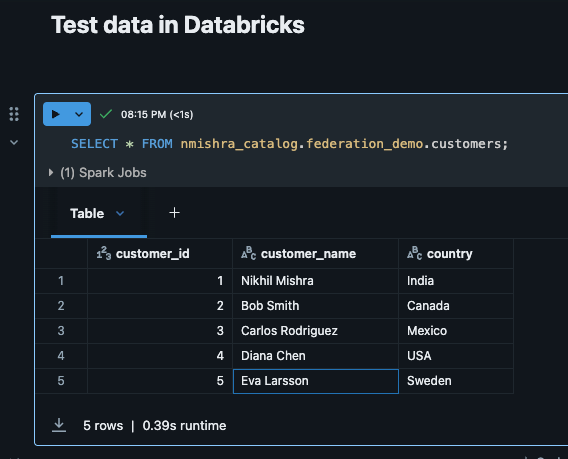
-- Grant access to your schema
GRANT EXTERNAL USE SCHEMA ON SCHEMA nmishra_catalog.federation_demo TO 'your-service-principal@company.com';
-- Or Grant access to specific tables
GRANT SELECT ON TABLE nmishra_catalog.federation_demo.orders TO 'your-service-principal@company.com';
GRANT SELECT ON TABLE nmishra_catalog.federation_demo.customers TO 'your-service-principal@company.com';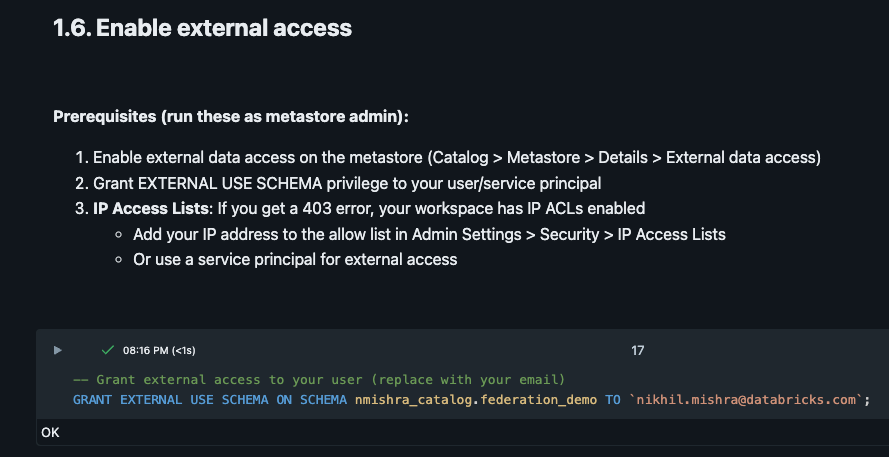
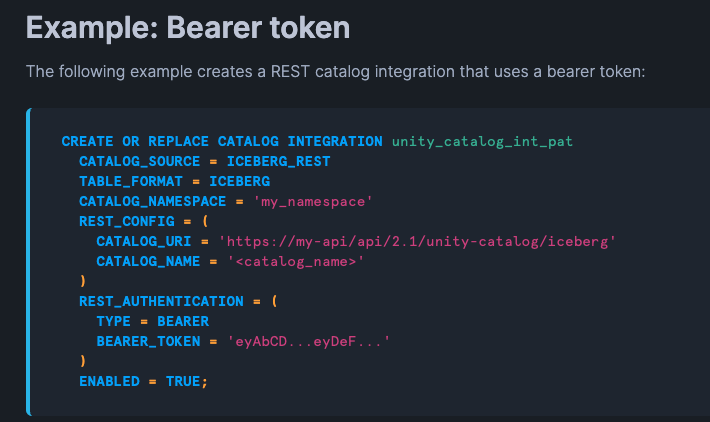
Step 2: Create Catalog Integration in Snowflake
Connect Snowflake to Unity Catalog:
Step 3: Create External Tables in Snowflake
Map Unity Catalog tables to Snowflake:
-- Create table that points to Unity Catalog
CREATE ICEBERG TABLE orders_from_databricks
CATALOG = nmishra_databricks_integration
CATALOG_TABLE_NAME = 'nmishra_catalog.federation_demo.orders';
-- Create another table
CREATE ICEBERG TABLE customers_from_databricks
CATALOG = nmishra_databricks_integration
CATALOG_TABLE_NAME = 'nmishra_catalog.federation_demo.customers';💡 Snowflake Private Preview: For automatic table syncing instead of manual table creation, Snowflake offers catalog-linked databases in private preview. This feature automatically syncs all Unity Catalog-managed Iceberg table metadata, eliminating the need to manually create individual tables. Learn more about catalog-linked databases and contact your Snowflake account team for access.
Step 4: Query Across Platforms
Now query Databricks tables directly from Snowflake:
-- Query your Databricks table from Snowflake
SELECT * FROM orders_from_databricks LIMIT 10;-- Query another table
SELECT * FROM customers_from_databricks LIMIT 10;Understanding Iceberg Table Metadata
When Snowflake accesses your Unity Catalog tables, it's reading rich Iceberg metadata that enables advanced capabilities:
Key Iceberg Features Your Tables Provide:
Time Travel: Query historical versions using snapshot IDs
Schema Evolution: Add/modify columns without breaking existing queries
ACID Transactions: All operations are atomic and consistent
File-level Statistics: Efficient query planning and pruning
Example Iceberg Metadata Response:
{
"format-version": 2,
"table-uuid": "b07b4027-344c-4e0a-85d0-7fa16dd49602",
"current-schema-id": 0,
"schemas": [{"fields": [
{"id": 1, "name": "customer_id", "type": "int"},
{"id": 2, "name": "customer_name", "type": "string"}
]}],
"current-snapshot-id": 1985908845652566551,
"snapshots": [{
"operation": "append",
"total-records": "5",
"total-data-files": "1"
}]
}
This metadata enables Snowflake to understand your table structure, access the correct data files in cloud storage, and leverage Iceberg's advanced features, such as time travel and schema evolution.
The Reverse Direction: Access Snowflake from Databricks
You can also query Snowflake tables from Databricks:
# Create connection to Snowflake
spark.sql("""
CREATE CONNECTION snowflake_conn
TYPE snowflake
OPTIONS (
host 'your-account.snowflakecomputing.com',
user 'your_user',
password secret('scope', 'password-key'),
warehouse 'COMPUTE_WH',
database 'MY_DB'
)
""")
# Query Snowflake data
df = spark.sql("""
SELECT customer_id, total_purchases
FROM snowflake_conn.my_db.customer_summary
WHERE total_purchases > 1000
""")
display(df)
Enhanced Bidirectional Capabilities: Snowflake Write Support (Private Preview)
While the above implementation enables Snowflake to read from Unity Catalog tables, Snowflake is also developing write capabilities that would allow direct writing to Unity Catalog from Snowflake.
Current Status: Private Preview
Catalog Linked Databases is currently in private preview and represents Snowflake's approach to enabling write operations to external Iceberg REST catalogs, including Unity Catalog. This feature was announced at Snowflake Summit 2025 and is expected to move to public preview soon.
What This Means for Your Architecture
Once available, this capability would enable:
True bidirectional write operations between Databricks and Snowflake
Elimination of data movement pipelines for cross-platform workflows
Unified governance with data written from either platform accessible to both
Conclusion: Federation Solves the Universal Challenge
The Federation approach through Unity Catalog directly addresses the most common interoperability challenge I observe with customers. By implementing bidirectional federation, organizations can finally achieve the goal of "write from anywhere, read from everywhere" without the traditional complexity of data movement and governance fragmentation.
Why This Architecture Matters
This isn't just about solving today's integration challenges—it's about building a future-proof data platform that can adapt to new technologies and requirements. Whether you're adding new query engines, implementing real-time analytics, or building advanced ML pipelines, Unity Catalog provides the foundation for a truly integrated data ecosystem.
The bottom line: The future of data platforms is not about choosing between Databricks and Snowflake—it's about seamlessly integrating both through Federation to leverage their unique strengths while maintaining unified governance and accessibility.
FAQ
1. Can Databricks read a Snowflake customer's Horizon catalog without using Snowflake compute? Yes, if the tables are Snowflake-managed Iceberg tables. Unity Catalog reads them directly from cloud object storage using Databricks compute through catalog federation — no Snowflake warehouse is spun up. This is generally available today.
2. What if the Snowflake tables aren't Iceberg? Regular (non-Iceberg) Snowflake tables can't be read from object storage. They're accessed through query federation over JDBC, which does use Snowflake compute. This also works today; it's just less cost-efficient than the Iceberg path.
3. So what's the first question to ask about any Snowflake table? "Is it a Snowflake-managed Iceberg table or not?" Iceberg → direct object-storage read, Databricks compute only. Not Iceberg → JDBC query federation, Snowflake compute. If a federated Iceberg table doesn't qualify for direct access, Databricks falls back to JDBC automatically, so queries still succeed.
4. Can other engines read Unity Catalog tables? Yes. Unity Catalog exposes managed Iceberg tables through the Iceberg REST Catalog API with credential vending, so Spark, Trino, Flink, Snowflake, DuckDB, and pandas can read them without copying data. This is GA.
5. Is write now possible from Snowflake into Unity Catalog, or is it still preview? It's GA, not preview anymore. Snowflake can insert, update, and create Iceberg tables governed by Unity Catalog on AWS and Azure (Azure reached GA in April 2026). Catalog-linked databases support read and write by default and auto-sync schemas and tables from Unity Catalog.
6. Does any of this physically copy data between platforms? For the Iceberg paths, no — engines read and write the same files in cloud storage under one governance layer. Only the JDBC query-federation path (non-Iceberg native tables) moves results through the source engine's compute.
7. What's the practical takeaway for a customer on both platforms today? If both sides standardize on Iceberg with Unity Catalog as the governing catalog, you get governed, bidirectional read and write across Databricks and Snowflake without building copy pipelines. The cost and performance benefits are largest when tables are Iceberg rather than native warehouse tables.
Ready to solve your interoperability challenges? Start with the Federation implementation guide above and gradually expand your capabilities. The future of data is unified through Federation, and Unity Catalog is the bridge that makes it possible.
Additional Resources and Documentation
Official Documentation
Snowflake: Configure a catalog integration for Unity Catalog
Databricks: Access Databricks tables from Apache Iceberg clients