
Understanding Embedding Model Pricing on Databricks– An End‑to‑End Guide
A practical guide to estimating embedding costs, comparing Databricks and OpenAI pricing, and understanding when Databricks’ managed platform delivers the best value.

How much will it cost to embed your documents? As machine‑learning and generative‑AI teams build retrieval‑augmented generation systems or semantic search platforms, this is one of the first questions stakeholders ask. Pricing depends on the provider, the model and—most importantly—how many tokens you process. In this article I’ll demystify the pricing for embedding models on Databricks and contrast it with OpenAI, show you how to estimate your token count and provide formulas you can reuse to budget your workloads.
Databricks embedding models: GTE and BGE Large
Databricks’ Mosaic AI Foundation Model Serving offers two base embedding models:

These models are fully managed within the Databricks Lakehouse Platform. That means your embeddings run next to your data: you can store source documents in Delta Lake, transform them with Spark or SQL, generate embeddings via the same API, index them with Databricks Vector Search, and control access with Unity Catalog—all without shipping data to an external service. For enterprises worried about governance or compliance, this “single platform” approach is a major advantage over standalone API providers.
*These dollar amounts assume the promotional DBU price of about $0.07 per DBU from Databricks’ pricing system table. Actual DBU rates vary by cloud and region; the Databricks pricing calculator, for example, shows higher hourly costs on some Azure regions.
DBUs and billing modes
A Databricks Billing Unit (DBU) represents compute consumed per hour, normalised across instance types and features. For model serving there are three billing modes:
Pay‑per‑token. Ideal for sporadic or low‑volume jobs. You pay only for the tokens processed by the model.
Provisioned throughput. For real‑time or high‑volume workloads you reserve one or more throughput bands. Each band provides a fixed token rate (9 450 tps for GTE, 11 800 tps for BGE Large) and costs a flat number of DBUs per hour. You can add bands to scale linearly and pay only for the number of bands and hours used.
Batch inference. Uses the same DBU/hr cost as provisioned throughput but runs as an asynchronous job with roughly 50 % higher throughput. Billing is per‑minute, so it’s well suited for embedding large corpora offline.
This flexibility lets you optimise for both bursty workloads (pay‑per‑token) and steady pipelines (throughput bands), all within the same API.
How to estimate your token count
Pricing is driven by tokens, not words. Tokens are sub‑word units used by the model’s tokenizer. For English text you can use the following rules of thumb:
1 token ≈ 4 characters.
1 token ≈ ¾ of a word (so 100 tokens ≈ 75 words).
1‑2 sentences ≈ 30 tokens; one paragraph ≈ 100 tokens.
1 500 words ≈ 2 048 tokens.
These ratios let you make back‑of‑the‑envelope estimates:
From words: tokens ≈ words / 0.75. A 750‑word document will be roughly 1 000 tokens.
From characters: tokens ≈ characters / 4. A ~4 000‑character block of text is about 1000 tokens.
For large datasets, calculate the average words per document, convert to tokens using the above ratios, then multiply by the number of documents.
If you need precision, OpenAI provides an interactive tokenizer and a tiktoken library help.openai.com that break your text into tokens exactly as the models do.
Pricing formulas you can reuse
Once you know your token count, you can estimate costs using simple formulas.
Once you know your token count, you can estimate costs.
Pay‑per‑token cost = (total tokens / 1 000 000) × (DBU per 1M tokens) × (DBU price).
Example: embedding 10 M tokens with GTE costs 10 M ÷ 1 M × 1.857 DBU × $0.07 ≈ $1.30.Provisioned throughput cost:
– Calculate bands needed: ceil(required tokens per second ÷ throughput per band).
– Hourly cost per band = DBU per hour per band × DBU price.
– Total cost = bands × hourly cost × hours reserved.Example: you need 18 000 tokens/s for 3 hours with GTE. One band handles 9 450 tps, so you reserve two bands. At $1.40/h per band, 2 bands × $1.40 × 3 h = $8.40.
Batch inference uses the same hourly rate but finishes jobs ~50 % faster.
How Databricks compares with OpenAI
OpenAI’s API offers three embedding models—text‑embedding‑3‑small, text‑embedding‑3‑large, and text‑embedding‑ada‑002—with fixed per‑token pricing and a 50 % discount for its batch API. The official pricing page lists the following costs per million input tokens:
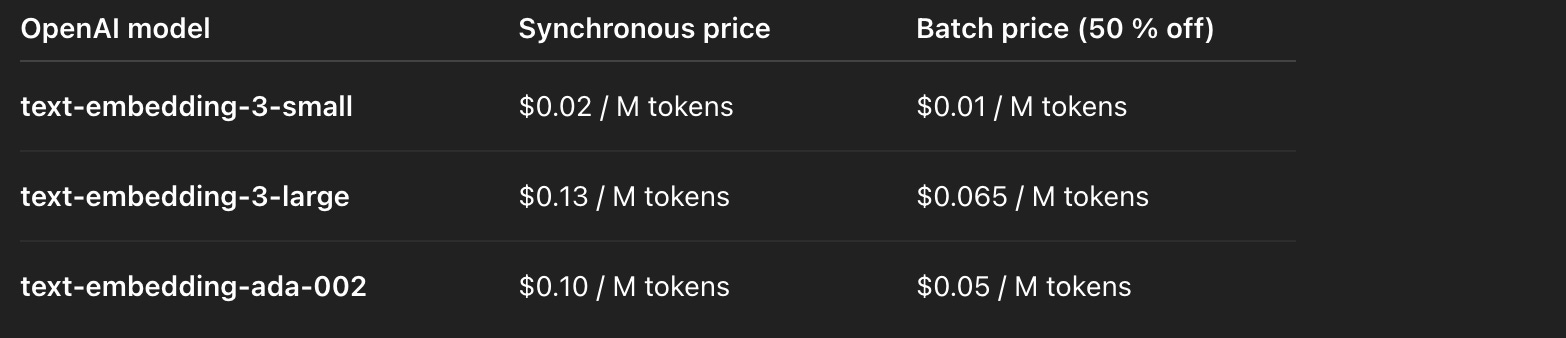
OpenAI’s unit prices are lower than Databricks, but there’s no throughput‑band concept or managed compute included—you pay for API calls only. Databricks, by contrast, integrates embedding serving with your Lakehouse data and can be more convenient for governance, security and performance. For on‑prem or self‑hosted deployments, the DBU model also lets you reserve capacity, which can reduce your effective cost per token when you run at high throughput.
Break‑even analysis: when does Databricks beat OpenAI?
To decide whether to pay OpenAI’s per‑token rates or reserve Databricks capacity, we need to find the break‑even point—the utilisation level at which the cost per million tokens is the same for both options. A Databricks throughput band has a fixed cost (DBU/hr × $0.07) and a fixed capacity. The utilisation percentage is the fraction of that capacity you actually use; if you run a GTE band at 4 700 tokens’s you’re at ~50 % utilisation (because its maximum is 9 450 tps). Below the break‑even utilisation, OpenAI may be cheaper; above it, Databricks’ cost per token drops below the API price.
Solving for utilisation yields the following thresholds (approximate numbers):
GTE vs text‑embedding‑3‑large (13¢/M): break‑even at about 32 % utilisation—roughly 10.8 M tokens per hour (~3 000 tps). At higher utilisation, GTE becomes cheaper.
GTE vs text‑embedding‑3‑large (Batch 6.5¢/M): needs ~63 % utilisation (~21.5 M tokens/h or 6 000 tps).
GTE vs ada‑002 (10¢/M): ~41 % utilisation (~14 M tokens/h) beats OpenAI; the batch price (5¢/M) requires ~82 % utilisation (~28 M tokens/h).
BGE Large shows similar patterns: ~30 % utilisation (~12.9 M tokens/h) beats text‑embedding‑3‑large, and ~40 % (~16.8 M tokens/h) beats ada‑002. The batch prices require ~61 % and ~79 % utilisation respectively.
These figures show that Databricks becomes cost‑competitive once you consistently process around 10–15 million tokens per hour. At full capacity (~9–12 k tokens per second) the cost per million tokens drops to about $0.04, roughly one‑third of OpenAI’s list price. For small or bursty jobs (less than a few million tokens per hour), OpenAI’s per‑call pricing may still be cheaper, but you trade off control, throughput guarantees and integration.
Putting it all together
Estimate your token volume. Use word‑ or character‑based heuristics or the tiktoken library to approximate the number of tokens.
Choose a billing mode. For occasional jobs, pay‑per‑token works well. For steady pipelines or latency‑sensitive applications, reserve throughput bands or use batch inference to reduce costs.
Apply the formulas. Multiply the DBU metrics by your DBU price to compute cost per million tokens or cost per band per hour, then scale by your usage.
Compare platforms. Consider the full picture: OpenAI’s low per‑token price lacks guaranteed throughput or governance; Databricks provides integrated data, compute and security with a pricing model that rewards sustained use.
Final thoughts: why Databricks is a great platform choice
Embedding costs don’t have to be mysterious. By breaking them down into tokens, DBUs and throughput you can budget with confidence. Databricks offers a unified Lakehouse environment where you can ingest data, generate embeddings, index them and serve them—without moving data off platform or stitching together multiple vendors. Its flexible pricing lets you start small with pay‑per‑token and scale seamlessly to reserved throughput, with significant cost advantages at higher volumes. For organisations that value governance, performance and cost predictability, Databricks isn’t just a model server—it’s a comprehensive platform for building production‑grade AI applications.