
Spark File Reads at Warp Speed: 3 maxPartitionBytes Tweaks for Small, Large, and Mixed File sizes
Scenario-Based Tuning: Optimizing spark.sql.files.maxPartitionBytes for Efficient Reads


In the world of big data, where terabytes and petabytes are the norm, Apache Spark has emerged as a leading distributed processing engine. However, harnessing Spark's full potential requires a deep understanding of its inner workings, especially when it comes to data partitioning. One crucial configuration parameter that significantly influences Spark's file reading performance is spark.sql.files.maxPartitionBytes. I have personally been able to speed up workloads by 15x by using this parameter.
This blog post provides a comprehensive guide to spark.sql.files.maxPartitionBytes, exploring its impact on Spark performance across different file size scenarios and offering practical recommendations for tuning it to achieve optimal efficiency.
“Important Note: This parameter specifically applies to reading data from files and does not affect partitioning during shuffle operations or other Spark transformations. It is effective only when using file-based sources such as Parquet, JSON, and ORC. Adaptive Query Execution (AQE) does not apply to this parameter.“
Why Partitioning Matters
Partitioning is the foundation of parallelism in Spark. By dividing data into smaller, independent chunks called partitions, Spark can distribute processing across multiple cores and executors, enabling concurrent execution and efficient resource utilization.
Here's why partitioning is crucial:
Parallelism: Each partition is processed independently by a task, allowing Spark to leverage multiple cores and executors for concurrent processing.
Resource Utilization: Proper partitioning ensures efficient resource utilization. Too few partitions can lead to underutilization of resources and data skew, where some partitions have significantly more data than others. Conversely, too many partitions can increase overhead due to excessive shuffling and task scheduling.
Data Locality: Spark strives to process data locally, meaning data is processed on the same node where it resides. Partitioning plays a crucial role in achieving data locality, minimizing data movement across the network.
Understanding spark.sql.files.maxPartitionBytes
spark.sql.files.maxPartitionBytes controls the maximum size of a partition when Spark reads data from files. By default, it's set to 128MB, meaning Spark aims to create partitions with a maximum size of 128MB each. This parameter directly influences the number of partitions created, which in turn affects parallelism and resource utilization during the file reading process.
Impact Across Different File Sizes
The impact of spark.sql.files.maxPartitionBytes varies depending on the size of the files being read. Let's explore three common scenarios:
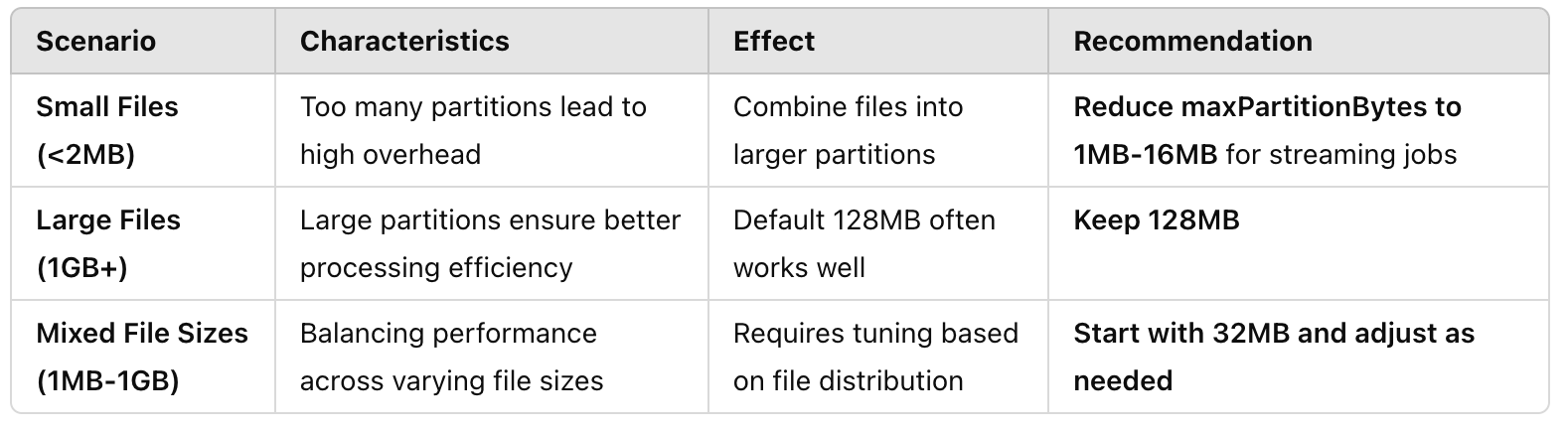
Scenario 1: 🟢 Lots of Small Files (<2MB)
When dealing with many small files, Spark's default behavior is to pack as many files as possible into a single partition until it reaches the maxPartitionBytes limit. This is because processing numerous small partitions can lead to significant overhead. However, decreasing spark.sql.files.maxPartitionBytes can significantly improve performance, especially in Spark Streaming jobs, by creating more, smaller partitions and increasing parallelism. This prevents cores from idling while waiting for large partitions to be processed, maximizing resource utilization and speeding up overall execution.
Recommendation: For small files, especially in streaming jobs, decrease spark.sql.files.maxPartitionBytes to a value between 1MB and 16MB.
Scenario 2: 🔵 Large Files (1GB)
For large files, spark.sql.files.maxPartitionBytes determines how many partitions Spark will create. With the default setting of 128MB, a 1GB file will be split into roughly 8 partitions. This often aligns well with Spark's general recommendation for partition sizes between 100-200MB for optimal performance.
Recommendation: For large files, the default value of 128MB often provides good performance.
Scenario 3: 🟠 Files of Varying Sizes (1MB to 1GB)
When reading files of varying sizes, Spark aims to create partitions with a size close to spark.sql.files.maxPartitionBytes. This means smaller files will be grouped together in a single partition, while larger files will be split into multiple partitions.
Finding the optimal value for spark.sql.files.maxPartitionBytes in this scenario requires careful consideration and experimentation. The ideal value depends heavily on the proportion of small and large files in your dataset.
Recommendation: Start with a lower value, around 32MB, and monitor performance. Adjust the value based on the observed performance and the distribution of file sizes in your dataset.
Caveats: Splittable File Types and Compression
It's crucial to consider the type of files and compression used when tuning spark.sql.files.maxPartitionBytes. Some compression formats, like gzip, create non-splittable files. This means Spark can't divide these files into smaller partitions, potentially limiting parallelism and impacting performance. In such cases, using splittable compression formats like bzip2 or lzo, or pre-splitting files into smaller chunks, can be beneficial.
Best Practices
❌ Avoid Gzip: Non-splittable, reduces parallelism.
✅ Prefer Bzip2 / LZO: Splittable, enables parallel reads.
⚡ Pre-split large files before ingestion if compression restricts partitioning.Monitor your Spark application's performance using the Spark UI. Pay close attention to task execution times, data skew, and shuffle behavior.
Adjust
spark.sql.files.maxPartitionBytesbased on the observed performance and the characteristics of your dataset.For small files, especially in streaming jobs, decrease the value to increase parallelism.
For large files, the default value often provides good performance.
For files of varying sizes, experiment to find the optimal balance.
Conclusion
By understanding the impact of spark.sql.files.maxPartitionBytes and following these best practices, you can fine-tune your Spark applications for optimal performance and efficiency when reading data from files. Remember that finding the perfect balance requires careful consideration of your specific cluster configuration, data characteristics, and application requirements.
Keep This Post Discoverable: Your Engagement Counts!
Your engagement with this blog post is crucial! Without claps, comments, or shares, this valuable content might become lost in the vast sea of online information. Search engines like Google rely on user engagement to determine the relevance and importance of web pages. If you found this information helpful, please take a moment to clap, comment, or share. Your action not only helps others discover this content but also ensures that you’ll be able to find it again in the future when you need it. Don’t let this resource disappear from search results — show your support and help keep quality content accessible!