
Orchestrating Databricks Workflows using Apache Airflow
Explore recent additions to the Airflow Databricks Operators

Introduction
Apache Airflow is a popular open source workflow orchestration tool. It builds a Directed Acyclic Graph (DAG) of tasks involved in a complex workflow and orchestrates running those tasks against compute platforms. It interfaces with compute platforms using Operators which are implemented using the APIs provided by the compute platforms to run tasks. Airflow Databricks operators have evolved quite a bit over the last few years and provide a lot of new features including cluster reuse, support for task groups, etc. This blog explores the various new features and shows examples of how to implement them in your use cases.
Brief overview of older Operators
The following set of Operators allow users to run a Databricks Job in two ways - either submit a fully specified Job and run it once or create a Job first (for reuse later) and then run it once. These operators have served us well for some time.
DatabricksSubmitRunOperator
This operator takes the complete specification of a Job and runs it once. You do not need to create a Job prior to using this Operator. The Job can contain a single task or an entire DAG. Along with the Job specification you can also specify a list of cluster configurations to be used for the tasks in the Job. The clusters are created according to the provided specifications and the Job is kicked off. The clusters are terminated at the end of the Job run. This operator creates a Jobs cluster when using the new_cluster Operator parameter. An existing All-purpose cluster can be reused, using the existing_cluster_id Operator parameter, if you want to avoid cluster startup latency.
DatabricksCreateJobsOperator
This operator can be used to create a Job in Databricks to be run later with the DatabricksRunNowOperator described in the next section. The Job can be a single task or a complex DAG. A list of cluster specifications can be specified and referenced in individual tasks. This is cost effective (compared to Databricks All-Purpose clusters) since it uses Databricks Jobs Clusters. But it suffers a bit on the performance side since the jobs cluster needs to be started on the job run each time.
DatabricksRunNowOperator
This operator is used to kickoff a Job that has already been defined in Databricks. It takes the job_id and job_name as required parameters and submits them to your Databricks instance using the Databricks API api/2.1/jobs/run-now endpoint. Optional parameters to this operator allow you to specify any job specific parameters.
Newer Operators
The newer Operators take advantage of TaskGroups introduced in AirFlow 2.0.
DatabricksTaskOperator
This operator was added as a generic Operator to override earlier Operators that were specific to running different types of tasks like Notebook tasks or SQL tasks.
DatabricksWorkflowTaskGroup
This is probably the most exciting Operator since the launch of Airflow Databricks Operators. The way the previously listed Operators are designed, any cluster that is specified as part of that Operator is created at the beginning of that task and shut down immediately after that task is done. This means that
You incur the performance penalty of constantly starting and stopping clusters.
You incur the cost of All-Purpose clusters for DatabricksSubmitRunOperator, instead of using a Jobs cluster which is considerably less expensive.
If your airflow DAG has lots of Databricks tasks, they can now be grouped under a Task Group. The compute resources used across the entire Task Group can be specified at the Task Group level and referenced in each task. The clusters are started at the beginning of the workflow, reused across all the tasks in the Task Group and shut down at the end of the entire workflow.
The first step in defining a DAG using a TaskGroup with Databricks Tasks is to create a job_cluster_spec like so:
job_cluster_spec = [
{
"job_cluster_key": "small",
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.xlarge",
"num_workers": 2,
},
},
{
"job_cluster_key": "large",
"new_cluster": {
"spark_version": "15.4.x-scala2.12",
"node_type_id": "i3.4xlarge",
"num_workers": 8,
},
},
]
Multiple clusters of different sizes can be defined here keyed by job_cluster_key and referenced in the individual tasks later.
The second step is to create a DAG
with DAG('databricks_task_group_dag',
start_date = days_ago(2),
schedule_interval = None,
default_args = default_args
) as dag:
Then, create the task groups as necessary. The following code creates two Databricks task groups separated by a BashOperator.
task_group_1 = DatabricksWorkflowTaskGroup(
group_id=f"test_workflow_anallan_1",
databricks_conn_id='databricks_default',
job_clusters=job_cluster_spec,
)
with task_group_1:
notebook_1 = DatabricksNotebookOperator(
task_id="workflow_notebook_1",
databricks_conn_id='databricks_default',
notebook_path="/path/to/notebook/for/Airflow Task 1",
source="WORKSPACE",
job_cluster_key="small",
)
notebook_2 = DatabricksNotebookOperator(
task_id="workflow_notebook_2",
databricks_conn_id='databricks_default',
notebook_path="/path/to/notebook/for/Airflow Task 2",
source="WORKSPACE",
job_cluster_key="small",
)
notebook_1 >> notebook_2
bash = BashOperator(task_id="bash", bash_command="echo hello")
task_group_2 = DatabricksWorkflowTaskGroup(
group_id=f"test_workflow_anallan_2",
databricks_conn_id='databricks_default',
job_clusters=job_cluster_spec,
)
with task_group_2:
notebook_3 = DatabricksNotebookOperator(
task_id="workflow_notebook_3",
databricks_conn_id='databricks_default',
notebook_path="/path/to/notebook/for/Airflow Task 3",
source="WORKSPACE",
job_cluster_key="large",
)
notebook_4 = DatabricksNotebookOperator(
task_id="workflow_notebook_4",
databricks_conn_id='databricks_default',
notebook_path="/path/to/notebook/for/Airflow Task 4",
source="WORKSPACE",
job_cluster_key="large",
)
notebook_3 >> notebook_4
The final step is to combine the task groups into a single DAG
task_group_1 >> bash >> task_group_2
The overall DAG looks like below:

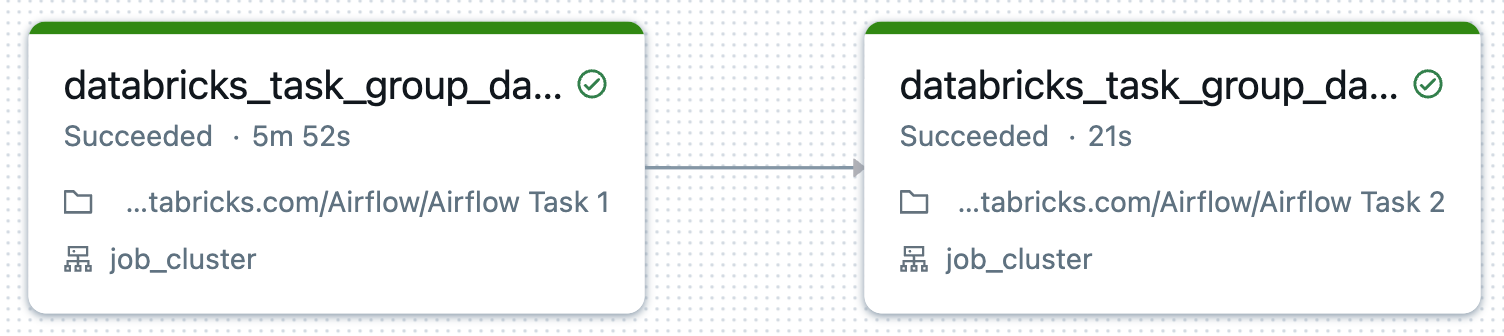
The individual task groups can be opened up to reveal the full DAG:

The individual task groups become separate Workflows in Databricks:

An individual Databricks Workflow looks like below:
Conclusion
As we have seen, when you are orchestrating multiple compute platforms in addition to Databricks as part of your data pipeline you can get a lot of benefits by collecting all your Databricks tasks into a AirFlow TaskGroup. With Databricks now supporting this concept, this is a much better way to design your pipelines.