

Introduction
Stream-static joins are one of the most powerful yet underutilized features in Apache Spark Structured Streaming. They enable real-time data enrichment by joining high-velocity streaming data with slowly-changing reference data stored in static tables. This pattern is essential for building production-grade streaming analytics pipelines that need contextual information.
In this deep dive, we'll explore how stream-static joins work, their performance characteristics, and implement a practical IoT data enrichment pipeline that demonstrates their power.
What Are Stream-Static Joins?
A stream-static join combines:
Streaming data: Continuous, high-velocity data (like IoT sensor readings)
Static data: Slowly-changing reference data (like device metadata, lookup tables)
Unlike stream-stream joins that require complex watermarking and state management, stream-static joins are stateless and have low latency because they don't need to buffer streaming data.
One Tap Could Make All the Difference
One surefire way to never see this content again? Scroll past without engaging. Search algorithms heavily rely on signals like likes and comments to decide whether a piece of content deserves to surface again, for you or anyone else. If you found this valuable, even in a small way, do consider hitting the like button or dropping a quick comment. It not only supports the content but helps others discover it too.
Key Characteristics
✅ Advantages
Stateless operation: No need to maintain join state across batches
Low latency: Immediate processing without buffering delays
Memory efficient: Only current batch held in memory
Simple semantics: Straightforward inner/left outer join logic
Automatic refresh: Static side automatically picks up latest data
⚠️ Considerations
Static side caching: May cache static data for performance (configurable)
Join key distribution: Ensure good partitioning for optimal performance
Data freshness: Static side updates aren't instantaneous across all executors
Architecture Pattern
Our IoT enrichment pipeline follows this pattern:
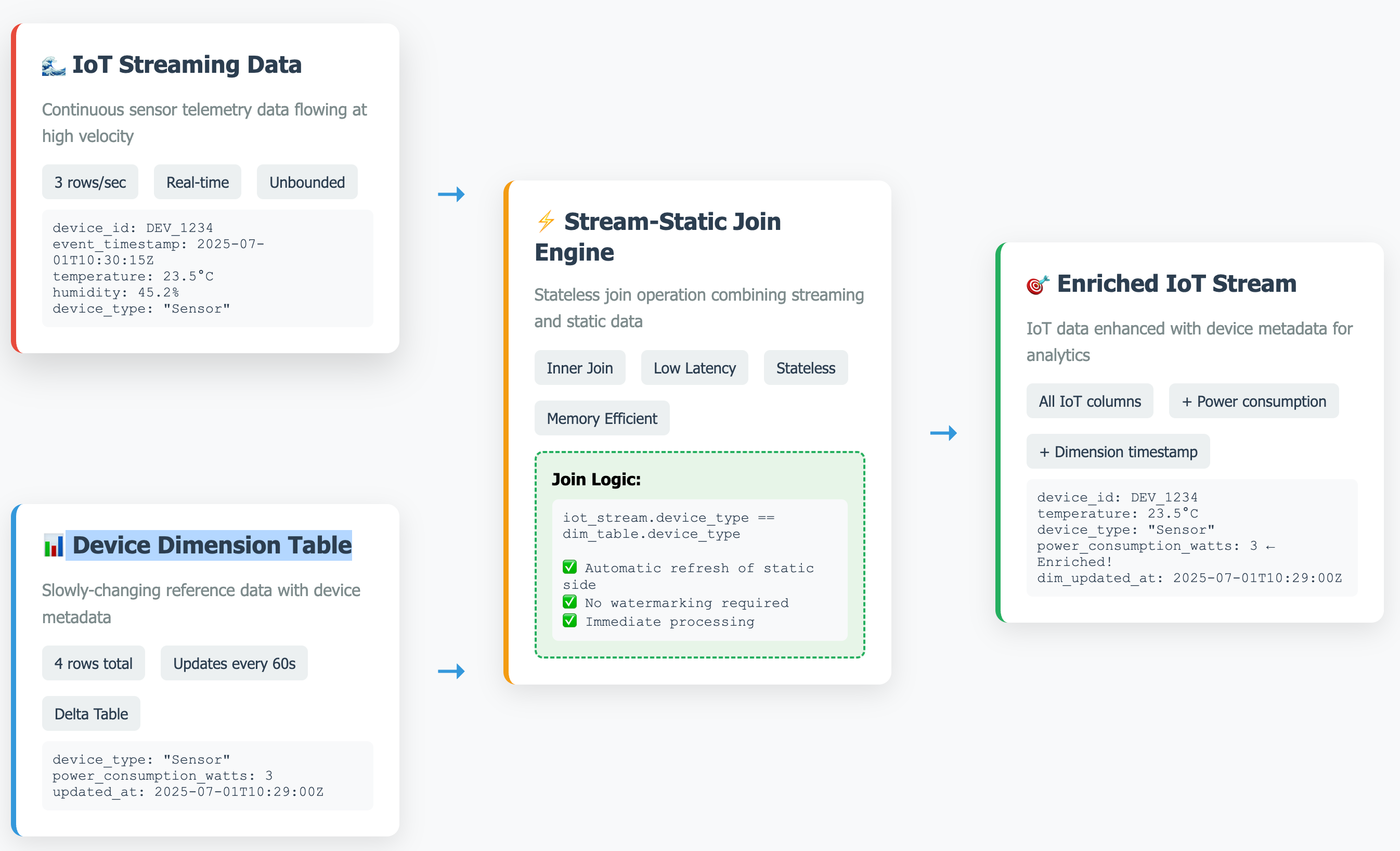
Implementation Walkthrough
1. Data Sources Setup
IoT Streaming Data (3 rows/second):
iot_streaming_df = (
iot_dataspec.build(withStreaming=True, options={'rowsPerSecond': 3})
.withColumn("event_timestamp", current_timestamp())
.withColumn("device_type", expr("...")) # Random device types
)Device Dimension Table (Updated every 60 seconds):
dim_fake_df = dim_dataspec.build(
withStreaming=True,
options={'rowsPerSecond': 1} # 4 rows over 60 seconds
)2. The Stream-Static Join
The magic happens here - joining streaming IoT data with static device metadata:
# Read the latest static dimension table
static_dim_df = spark.read.table("DIM_DEVICE_TYPE")
# Perform the stream-static join
enriched_iot_df = (
iot_streaming_df
.join(
static_dim_df,
iot_streaming_df.device_type == static_dim_df.device_type,
"inner"
)
.select(
# IoT columns: device_id, temperature, humidity, etc.
# Dimension columns: power_consumption_watts, updated_at
)
)3. Processing Pipeline
The enriched stream can then be:
Written to Delta tables for analytics
Sent to downstream systems
Used for real-time alerting
Aggregated for dashboards
Advanced Patterns
1. Multi-Level Enrichment
Chain multiple stream-static joins for complex enrichment:
enriched_df = (
stream_df
.join(device_dim_df, "device_id") # Device metadata
.join(location_dim_df, "location_id") # Location data
.join(customer_dim_df, "customer_id") # Customer info
)2. Conditional Enrichment
Use case-when logic for selective enrichment:
enriched_df = stream_df.join(
dim_df,
when(col("enrichment_flag") == "Y", col("device_type")).otherwise(lit(None))
)Common Pitfalls and Solutions
1. Stale Static Data
Problem: Static side doesn't reflect recent updates
Solution: Implement proper cache invalidation and refresh strategies. Halt the application and cut a ticket to investigate.
2. Memory Pressure
Problem: Large dimension tables cause OOM errors Solution: Use broadcast joins for small tables, partition large ones
3. Late Arriving Dimension Updates
Problem: Dimension updates arrive after streaming data
Solution: Implement eventual consistency patterns with reprocessing for only the incomplete data
Conclusion
Stream-static joins are a cornerstone pattern for real-time data enrichment in modern streaming architectures. They provide the perfect balance of performance, simplicity, and functionality needed for production systems.
The IoT enrichment pipeline we explored demonstrates how to:
✅ Join streaming telemetry with device metadata
✅ Achieve low-latency enrichment at scale
✅ Monitor and optimize performance
✅ Handle dimension updates gracefully
By mastering stream-static joins, you can build robust, performant streaming pipelines that deliver real-time insights with rich contextual information.
Next Steps
Experiment with different trigger intervals and batch sizes
Implement custom partitioning strategies for your use case
Add comprehensive monitoring and alerting
Link to code
References
Ready to implement stream-static joins in your architecture? Start with a simple use case and gradually add complexity as you gain confidence with the pattern.

