

UPDATE: This is a strictly worse version of the updated one.
Don’t you hate it when your employees run up a thousand dollar tab on Claude API calls inside of a week and then hit you with this look when you tell them that was the budget for the quarter?

I might have something for that.
One of the cornerstones of the Databricks value-add in AI is that we are a model provider neutral platform. We offer native pay-per-token hosting for open source model families like Llama, Gemma, and GPT OSS and we have first party connections with Claude, OpenAI, and Gemini. However, if you want to control costs, our current AI Gateway offering only allows you to do so via QPM rate limiting. QPM certainly has its use cases, but the majority of companies don’t care how many times per minute their employees or end users hit a model; they care about how much it’s going to cost them.
Luckily with Lakebase, token-based rate limiting is now possible and the implementation is simple: a user submits a request, which is then validated by the endpoint via queries to two Lakebase tables, the first to determine that user’s token limits and the second to determine how far into those limits they already are. If the user is out of tokens, a cutoff message is returned and the request does not hit the FM. Otherwise, the request is passed to the FM and the payload is written back to Lakebase so that the user’s total token count is updated. Finally, the response is returned to the end user with a message noting their remaining token balance.
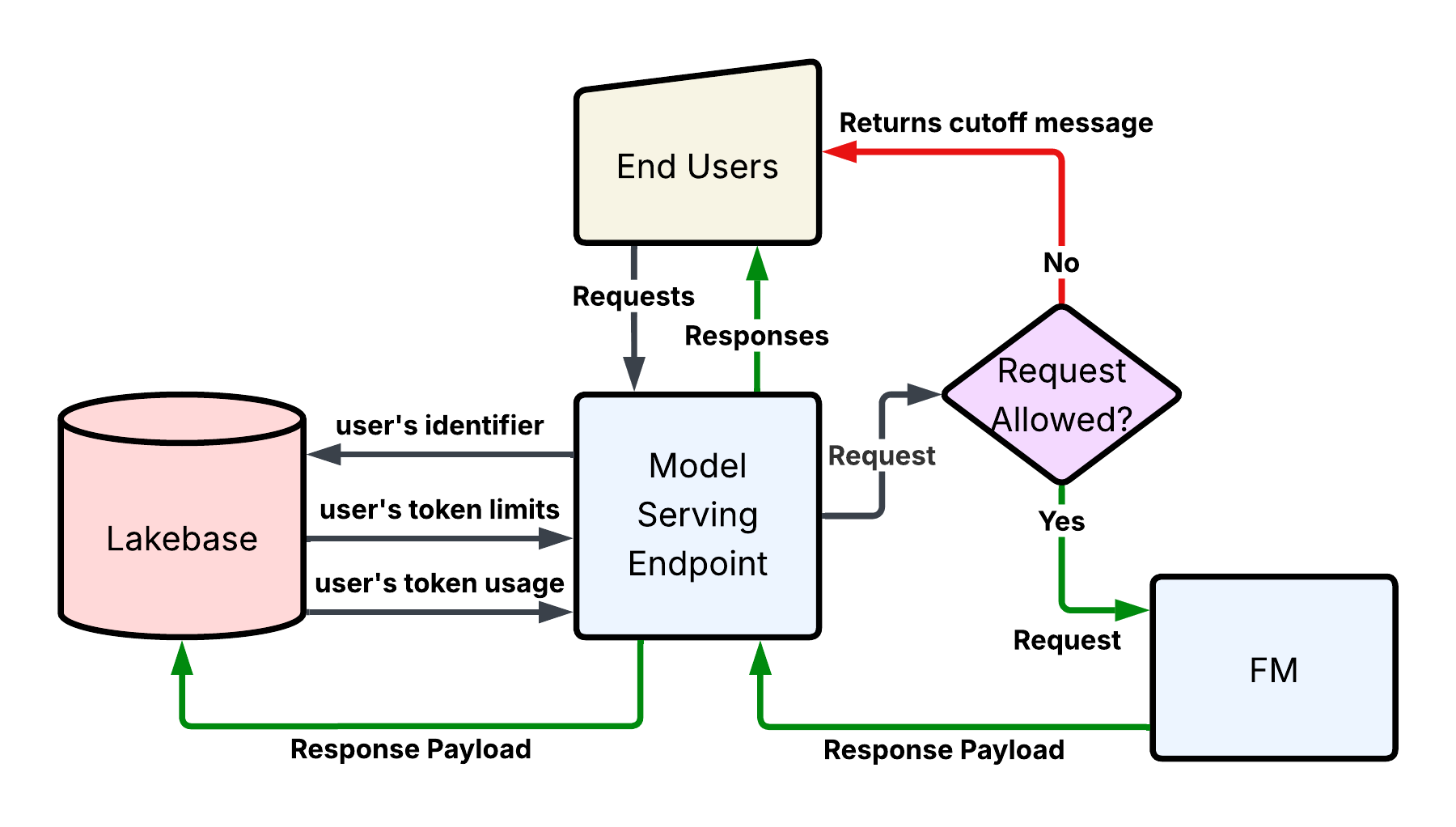
Great, let’s see some code then, huh?
First we need to install psycopg2:
%pip install psycopg2
dbutils.library.restartPython()And set a few environment variables from a Lakebase instance:
import mlflow.pyfunc
import os
os.environ[’OPENAI_API_KEY’] = ‘’ # or whatever FM API key
os.environ[’DATABRICKS_TOKEN’] = ‘’
os.environ[’POSTGRES_HOST’] = ‘’
os.environ[’POSTGRES_DBNAME’] = ‘databricks_postgres’ # or ‘’
os.environ[’POSTGRES_USER’] = ‘’
os.environ[’POSTGRES_SSLMODE’] = ‘’
os.environ[’POSTGRES_PORT’] = 5432 # or ‘’
os.environ[’POSTGRES_PASSWORD’] = ‘’For the demonstration, let’s create a couple quick example tables and populate the user_token_limits table with a record:
%sql
-- Create token_usage table for tracking all API calls
CREATE TABLE IF NOT EXISTS token_usage (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
user_name VARCHAR(255) NOT NULL,
model_name VARCHAR(100) NOT NULL,
prompt_tokens INTEGER NOT NULL,
completion_tokens INTEGER NOT NULL,
total_tokens INTEGER NOT NULL,
request_timestamp TIMESTAMP NOT NULL,
request_id VARCHAR(255),
response_content STRING,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Create user_token_limits table for managing quotas
CREATE TABLE IF NOT EXISTS user_token_limits (
id BIGINT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
user_name VARCHAR(255) NOT NULL,
model_name VARCHAR(100) NOT NULL,
token_limit INTEGER NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- Insert sample user limit
INSERT INTO user_token_limits (user_name, model_name, token_limit)
VALUES (’test.user@databricks.com’, ‘gpt-4.1-2025-04-14’, 1000);Obviously you could do the above in the PostgreSQL editor, but might as well use the notebook since we’re here.
And now we can define our rate limiter. Note that this is extremely flexible. Any kind of rate limiting you can think up is doable as long as you can translate it into PostgreSQL. That means per user, per user per model, per user per model per unit time, and so on are all at your fingertips. I’m going to define a simple per user per model rate limit as hinted above and populate that with a token cutoff of just 1000 tokens on GPT 4.1:
import mlflow
from mlflow.types import DataType, Schema, ColSpec
import mlflow.models
import json
import pandas as pd
import psycopg2
import requests
from datetime import datetime
import os
class TokenLimitedGatewayModel(mlflow.pyfunc.PythonModel):
def load_context(self, context):
“”“Initialize database connection and endpoint URL”“”
self.conn = psycopg2.connect(
host=os.environ[’POSTGRES_HOST’],
dbname=os.environ[’POSTGRES_DBNAME’],
user=os.environ[’POSTGRES_USER’],
password=os.environ[’POSTGRES_PASSWORD’],
port=int(os.environ.get(’POSTGRES_PORT’, 5432)),
sslmode=os.environ.get(’POSTGRES_SSLMODE’, ‘require’)
)
self.conn.autocommit = True
self.cursor = self.conn.cursor()
# FM endpoint
self.fm_endpoint = “”
# Get API token from environment if needed
self.api_token = os.environ.get(’DATABRICKS_TOKEN’, ‘’)
print(”Model context loaded successfully”)
def predict(self, context, model_input):
“”“Process request with token limit checking”“”
# Handle different input types
if isinstance(model_input, pd.DataFrame):
# Convert DataFrame to dict and get first row
if len(model_input) > 0:
data = model_input.iloc[0].to_dict()
else:
return {”error”: “Empty input DataFrame”}
elif isinstance(model_input, dict):
data = model_input
else:
# Try to convert to dict
try:
data = dict(model_input)
except:
return {”error”: f”Unsupported input type: {type(model_input)}”}
# Extract and parse messages
messages = data.get(”messages”, [])
if isinstance(messages, str):
try:
messages = json.loads(messages)
except json.JSONDecodeError:
return {”error”: “Invalid JSON in messages field”}
# Extract parameters with defaults
user_name = str(data.get(”user_name”, “test.user@databricks.com”))
model_name = str(data.get(”model”, “gpt-4.1-2025-04-14”))
# Handle max_tokens in case missing, this is on request side, not the rate limiter
max_tokens_raw = data.get(”max_tokens”, 128)
if pd.isna(max_tokens_raw) or max_tokens_raw is None:
max_tokens = 128
else:
max_tokens = int(max_tokens_raw)
# Handle temperature in case missing
temperature_raw = data.get(”temperature”, 0.7)
if pd.isna(temperature_raw) or temperature_raw is None:
temperature = 0.7
else:
temperature = float(temperature_raw)
# Check current token usage
self.cursor.execute(”“”
SELECT COALESCE(SUM(total_tokens), 0) as total_used
FROM token_usage
WHERE user_name = %s AND model_name = %s
“”“, (user_name, model_name))
result = self.cursor.fetchone()
tokens_used = int(result[0]) if result and result[0] else 0
# Check user’s token limit
self.cursor.execute(”“”
SELECT token_limit
FROM user_token_limits
WHERE user_name = %s AND model_name = %s
“”“, (user_name, model_name))
limit_result = self.cursor.fetchone()
if not limit_result:
return {”error”: f”No token limit found for user {user_name} and model {model_name}”}
token_limit = int(limit_result[0])
# Check if limit exceeded
if tokens_used >= token_limit:
return {
“error”: f”Token limit exceeded. Used: {tokens_used}, Limit: {token_limit}”,
“tokens_used”: tokens_used,
“token_limit”: token_limit
}
# Prepare request for FM endpoint
fm_request = {
“messages”: messages,
“max_tokens”: max_tokens,
“temperature”: temperature
}
headers = {
“Content-Type”: “application/json”
}
if self.api_token:
headers[”Authorization”] = f”Bearer {self.api_token}”
try:
# Call FM endpoint
response = requests.post(
self.fm_endpoint,
json=fm_request,
headers=headers,
timeout=30
)
response.raise_for_status()
fm_response = response.json()
# Extract token usage from response
usage = fm_response.get(”usage”, {})
prompt_tokens = int(usage.get(”prompt_tokens”, 0))
completion_tokens = int(usage.get(”completion_tokens”, 0))
total_tokens = int(usage.get(”total_tokens”, 0))
# Log token usage to database
self.cursor.execute(”“”
INSERT INTO token_usage (
user_name,
model_name,
prompt_tokens,
completion_tokens,
total_tokens,
request_timestamp,
request_id,
response_content
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
“”“, (
user_name,
model_name,
prompt_tokens,
completion_tokens,
total_tokens,
datetime.utcnow(),
fm_response.get(”id”, “”),
json.dumps(fm_response)
))
# Add usage info to response
fm_response[”usage_info”] = {
“tokens_used_total”: tokens_used + total_tokens,
“token_limit”: token_limit,
“tokens_remaining”: token_limit - (tokens_used + total_tokens)
}
return fm_response
except requests.exceptions.RequestException as e:
return {
“error”: f”Failed to call FM endpoint: {str(e)}”,
“tokens_used”: tokens_used,
“token_limit”: token_limit
}
except Exception as e:
return {
“error”: f”Unexpected error: {str(e)}”,
“tokens_used”: tokens_used,
“token_limit”: token_limit
}The astute among you will draw attention to any of the following annoyances:
Now I need to pay for a custom model serving endpoint on top of my token costs to the foundation model(s), that’s so counterproductive!
Ok fair, but a minimum provisioned CPU endpoint costs $0.28 per hour and can handle a relatively large request volume since it’s not actually performing any calculations except a simple comparison operation to check your token limits. If you have hundreds of users calling this endpoint per second, then yeah it might break, but for a lot of companies this guaranteed hit of $0.28/hr is worth the protection against a potentially much larger bill if some of my employees run up a huge tab without me knowing.
This is going to add latency, and at scale I can’t abide this
Also fair, and I would say bulk queries should certainly be run through
ai_query()to obtain serious scale via parallel requests, but what about all your tinkerers? Your BI Analysts, your data scientists, your citizen GenAI practitioners, etc.? Are they hitting 100 QPS?
Every new model is going to require me to set up a new config, ain’t nobody got time for that
Yes, but, per user per model rate limiting is just an example I used to show how much specificity you could add to this if and only if you wanted to. You could instead set this up one time to handle requests to any of the main endpoints your employees are calling (new model additions are likely to follow the same API patterns as their predecessors) and only limit per user or per user per unit time. This simplifies the deployment and management.
With the totally reasonable objections out of the way, let’s log and register this thing and then I’ll leave you with a couple concluding thoughts:
# Define signature - all fields required
input_schema = Schema([
ColSpec(DataType.string, “messages”),
ColSpec(DataType.string, “user_name”),
ColSpec(DataType.string, “model”),
ColSpec(DataType.long, “max_tokens”),
ColSpec(DataType.double, “temperature”)
])
output_schema = Schema([
ColSpec(DataType.string, “response”)
])
signature = mlflow.models.ModelSignature(
inputs=input_schema,
outputs=output_schema
)
pip_requirements = [
“mlflow”,
“requests”,
“psycopg2-binary”,
“pandas”
]
# Create test DataFrame (simulating what serving endpoint sends)
test_df = pd.DataFrame([{
“messages”: json.dumps([
{”role”: “user”, “content”: “Say ‘Test Successful’ and nothing else”}
]),
“user_name”: “test.user@databricks.com”,
“model”: “gpt-4.1-2025-04-14”,
“max_tokens”: 50,
“temperature”: 0.7
}])
print(”Test input DataFrame:”)
print(test_df)
model = TokenLimitedGatewayModel()
model.load_context(None)
print(”\nTesting with DataFrame input...”)
result = model.predict(None, test_df)
if “error” not in result:
print(”Test successful!”)
if “choices” in result:
print(f”Response: {result[’choices’][0][’message’][’content’]}”)
print(f”Usage info: {result.get(’usage_info’, {})}”)
else:
print(f”Error: {result[’error’]}”)
# Log the model
with mlflow.start_run() as run:
mlflow.pyfunc.log_model(
artifact_path=”token_gateway”,
python_model=TokenLimitedGatewayModel(),
pip_requirements=pip_requirements,
signature=signature
)
model_uri = f”runs:/{run.info.run_id}/token_gateway”
print(f”Model logged with URI: {model_uri}”)
print(f”Run ID: {run.info.run_id}”)
# Register to Unity Catalog
catalog = “”
schema = “”
model_name = “token_limited_gateway”
registered_model = mlflow.register_model(
model_uri=model_uri,
name=f”{catalog}.{schema}.{model_name}”,
tags={
“use_case”: “rate_limiting”,
“model_type”: “gateway”,
“backend”: “openai_gpt4”,
“database”: “lakebase_postgres”,
“version”: “dataframe_compatible”
}
)All done.
Now we have another expense that can’t scale, adds latency, and is another component to maintain.
Or, we have a relatively low cost insurance policy against runaway token costs for employees we really wanted to enable on all our LLM endpoints but have previously been too worried about cost controls to do so.
Only you know which of these is the “correct” interpretation. My guess is both are right depending on your users and use case. It’s not perfect, but I said it was medieval right at the outset.
Cheers and happy coding!