
Doctors HATE this one dependency trick!
A quick guide to dependency management for machine learning using MLflow 3+.

Life was promised to be simple. You log your model and then you deploy the model. This is supposed to be easy! But even if everything works perfectly in your notebook, once you deploy it, dependency issues that you have never seen before pop up.

Most dependency resolution issues are because of conflicting transitive dependencies. Here is what most data scientists are doing today:
Experiment in notebooks, adding new libraries via pip within a notebook.
Log models using
mlflow.Register a model to UC and deploy.
Cross your fingers and hope everything works.
[optional] Get frustrated with Model Serving.
mlflow only infers the direct dependencies when you log a model. It identifies them by examining the flavor and the packages used in the model’s predict function. For more information, check out mlflow.models.infer_pip_requirements().
Usually, this means that dependencies are only resolved during Model Serving, which means dependency errors are not caught until then. Waiting for the Serverless compute and the container to build will only extend the developer loop, making it harder to iterate.
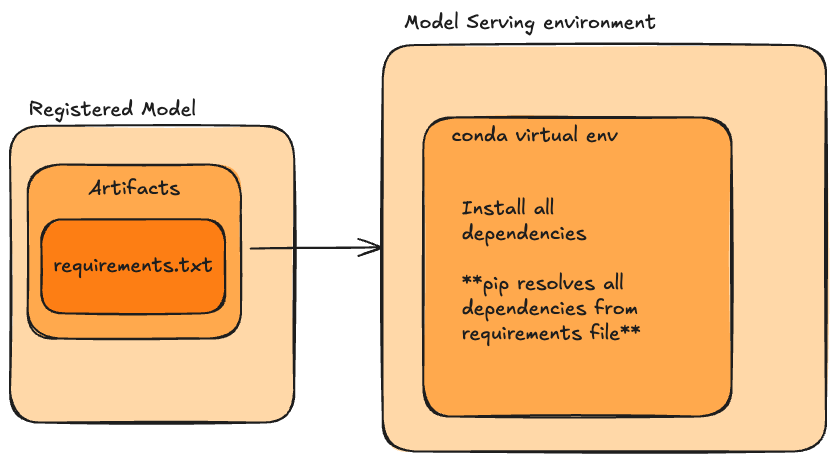
Lock your dependencies during development
In mlflow 3+, you can enable dependency locking with uv, which would allow you to use the standard mlflow logging workflow.
import os
os.environ["MLFLOW_LOCK_MODEL_DEPENDENCIES"] = "true"
# Now when you log your model, MLflow will capture
# both direct AND transitive dependencies
mlflow.sklearn.log_model(
model,
"my_model",
)Your workflow does not have to change at all. You can still use extra_pip_requirements, pip_requirements, or allow mlflow to infer all direct dependencies. The environment variable now enables uv to resolve dependencies during logging time and will capture pinned direct and transitive dependencies. Now, your requirements.txt file will contain all the dependencies you need.
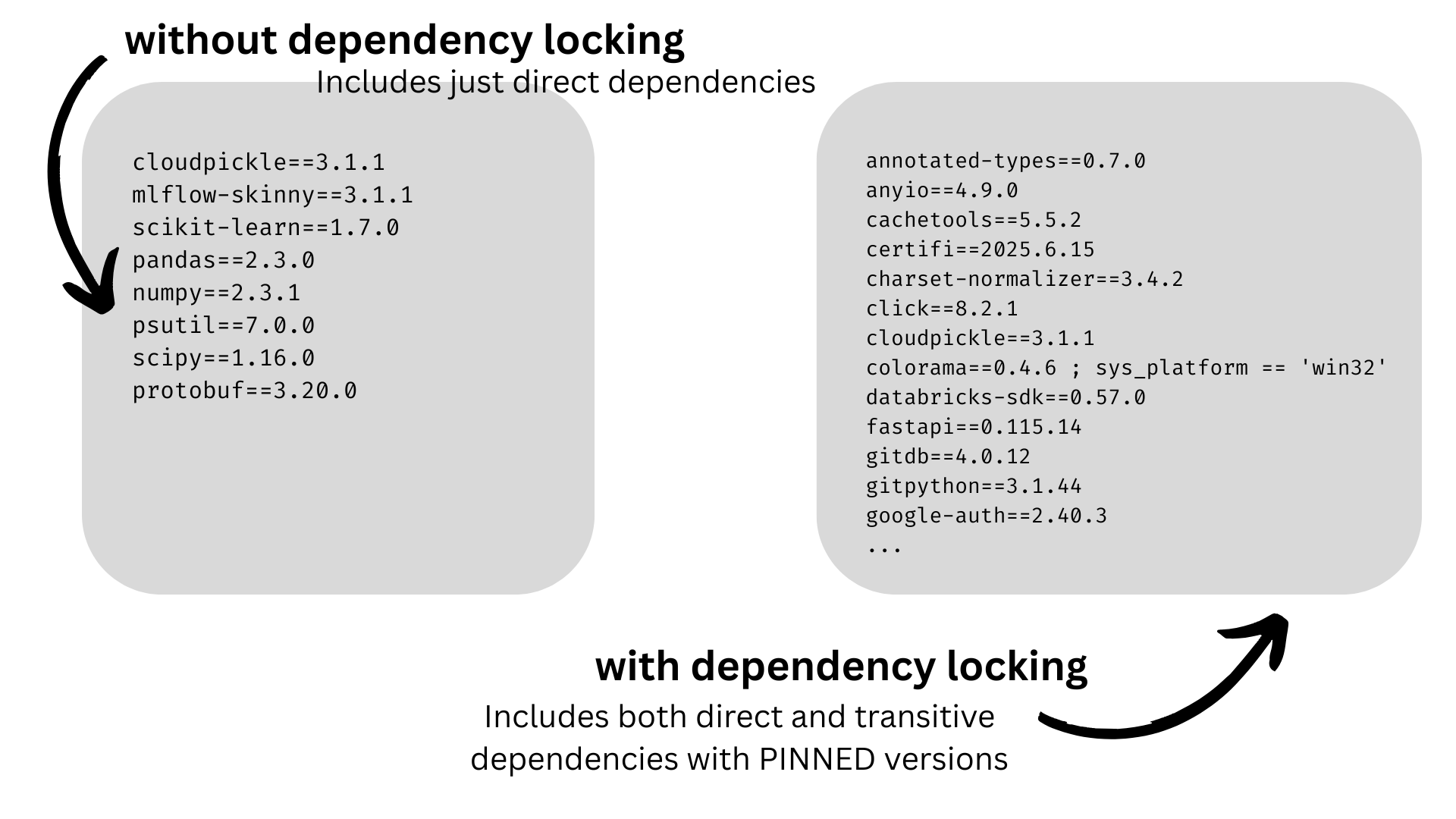
Dependency resolution occurs during model logging time instead of serving time, and we have automatic dependency locking when logging a model.
However, since uv resolves all of the dependencies, the transitive dependencies captured are often more recent than the packages installed by default on the DBR. So, we will usually get ‘warnings’ that the dependencies captured by uv are different from the transitive dependencies in the environment. Why is this a problem? Our training environment and serving environment are still different, which means we could still get behavior differences between our notebook and our deployment.

In the above example, we can see that cloudpickle often resolves to version 3.1.1, but in our recent DBRs, cloudpickle version 2.2.1 is installed. This is especially important because cloudpickle will always be a transitive dependency as mlflow relies on it.
Using Databricks Asset Bundles
We can resolve the inconsistency between the notebook environment and the serving environment using Databricks Asset Bundles. If we have a `dev` workspace and a `test` workspace, then we can use mlflow and uv to generate the requirements lock file in the `dev` workspace and add the requirements lock file as a dependency for the `test` workspace.
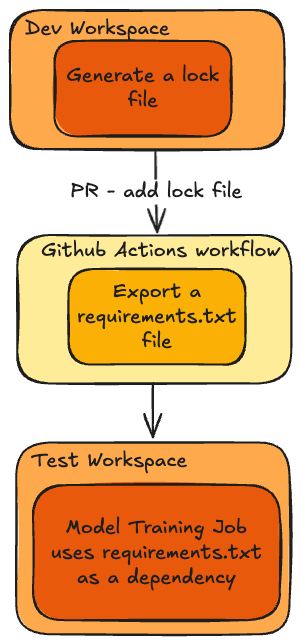
This can all be easily orchestrated using Databricks Asset Bundles and Lakeflow Jobs. By installing the requirements lock file, we can override any conflicting transitive dependencies in the DBR and ensure that the training and serving environments are the exact same. Here is an example job config:
resources:
jobs:
my_job:
tasks:
- task_key: train_model
libraries:
- requirements: ./requirements.txt # Pre-resolved dependenciesNow the entire pipeline uses the same dependencies from development through production.
Dependency management is important!
Dependency management is probably not the most exciting part of MLOps but it can easily become a migraine. The few extra minutes you spend considering dependency management will save you lots of time debugging serving deployment failures.
As always, let us know if you have any questions!
Excellent stuff! This is a huge unlock for any team that requires absolute control over their dependencies in their serving environment.