
Databricks Zerobus Ingest — The Best Bus Is No Bus
You don't need a sledgehammer to hang a picture

The Problem
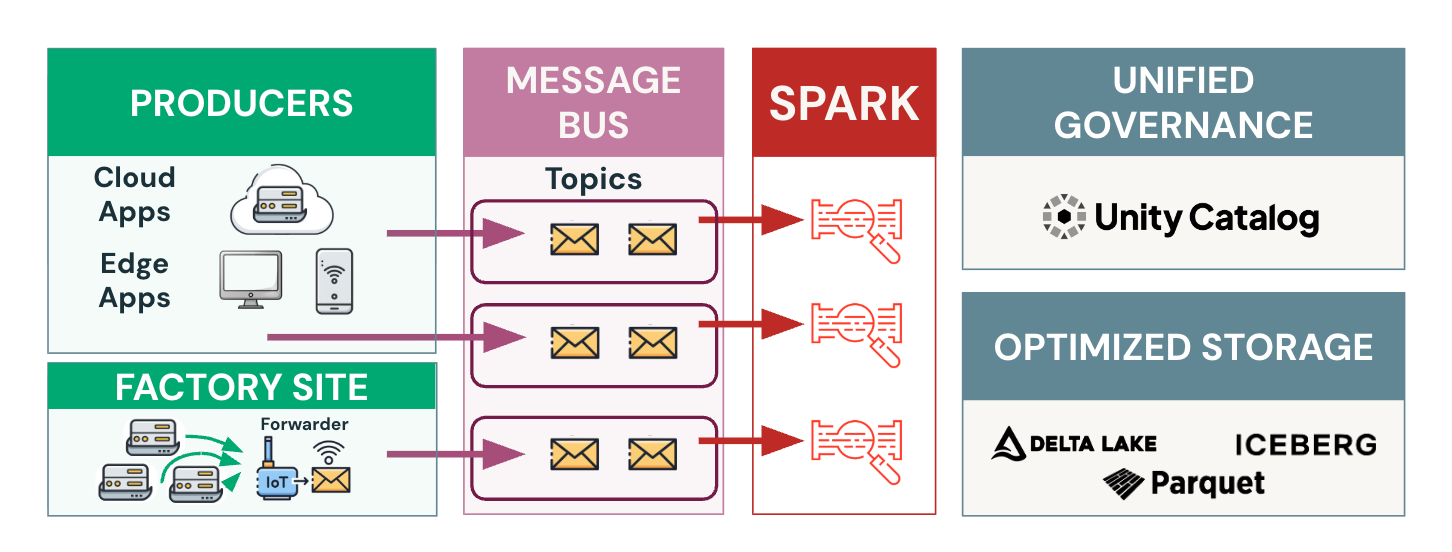
Complex Ingestion Architecture
Today’s data teams face a common challenge: streaming data from applications to their Lakehouse requires maintaining complex infrastructure. The typical setup involves managing a message bus like Kafka, configuring connectors, monitoring pipelines, and dealing with significant operational overhead and costs—all just to move data from point A to point B.
Managed Bus Don’t Solve Everything
While Amazon Managed Streaming for Apache Kafka(Amazon MSK) removes the burden of managing servers, it doesn’t eliminate your responsibility for the message bus itself. You’re still on the hook for capacity planning, topic and partition design, producer and consumer tuning, monitoring and alerting, and upgrade timing. Managed services make these tasks less manual, but upgrades remain risky and the operational complexity persists.
Cost management is another pain point. Amazon Managed Streaming for Apache Kafka(Amazon MSK) bills can balloon quickly due to over-provisioned brokers, excess partitions, high replication factors, and long retention periods. AWS manages the infrastructure, but not your spending discipline—that’s still your problem.
What You Actually Need
A fully abstracted streaming service that eliminates cluster management entirely, letting you focus on building data products instead of babysitting message bus infrastructure.
Customer Story
A leading automotive startup
The Challenge
A rapidly growing automotive startup was processing massive device data volumes from Go applications. After essential first-level processing, they needed to stream data to their data lake for near real-time analytics. To avoid the complexity of managing Kafka or similar message bus infrastructure, they took a shortcut: direct writes to their data warehouse with append-only inserts.
Initially simple, this approach quickly hit walls. As volumes grew, they vertically scaled, then horizontally distributed producers across multiple warehouse instances. Small but relentless queries created network bottlenecks. Excessive delta commits from numerous producers killed throughput. They hit soft limits on connections and write operations. To keep data flowing, they over-provisioned compute—watching costs balloon without proportional gains.
The Solution
Zerobus Ingest provided the purpose-built ingestion layer they needed. Their Go applications integrated the SDK with minimal code changes—same append-only pattern, properly architected. The Write-Ahead Logging (WAL) based system handled buffering and batching, while automatic recovery managed network issues that previously caused data loss.
Data now lands directly in Delta tables, eliminating the warehouse intermediary. The result: lower latency, higher throughput, dramatically reduced costs, and one less system to manage. They got the simplicity of direct writes with the scalability of proper streaming—at a fraction of Kafka’s cost.
Zerobus Ingest
Simplifying Real-Time Data Ingestion
Overview
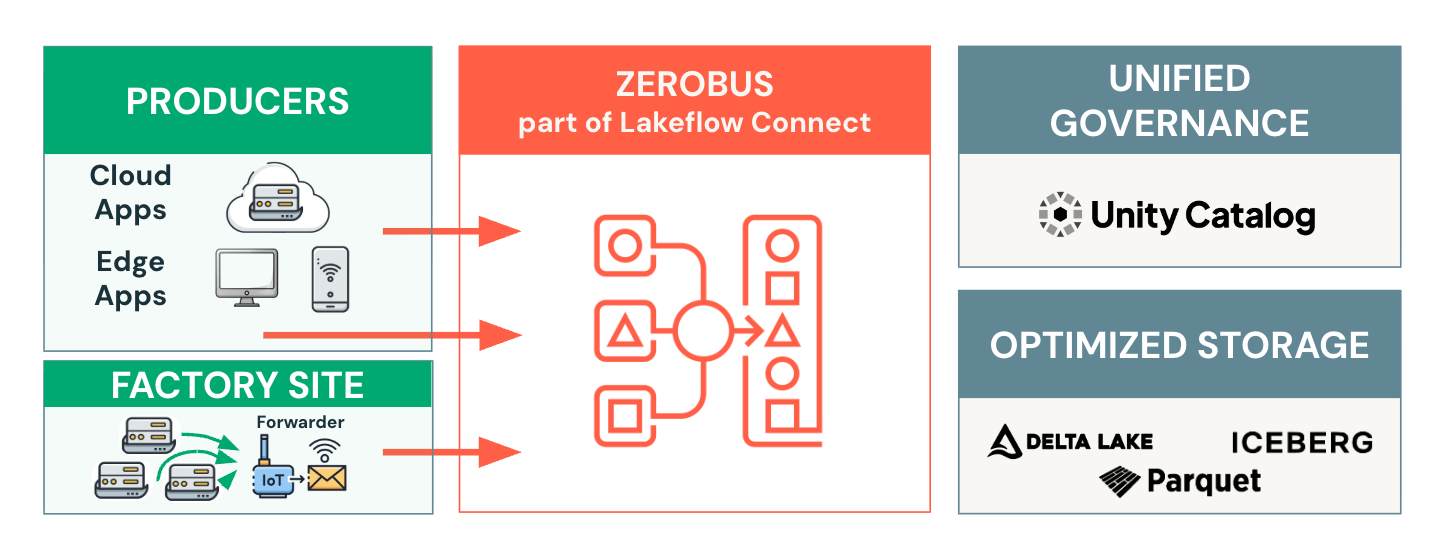
Zerobus Ingest is a fully managed, zero-configuration service that enables record-by-record data ingestion directly into Delta tables. No more intermediate message buses. No more complex configurations. Just point your application at an endpoint and start sending data. The Zerobus Ingest API buffers transmitted data before adding it to a Delta table. This buffering creates an efficient and durable ingestion mechanism that supports a high volume of clients with variable throughput.
Before:
After:
Features
Zerobus Ingest leverages a Write Ahead Log (WAL) architecture that enables it to store and acknowledge accepted records quickly, delivering low write latency for your applications. The system is backed by persistent disk storage where both the Write Ahead Log (WAL) and checkpoints are maintained, enabling several powerful capabilities:
Automatic Recovery - Network issues are handled transparently by the SDK. It automatically reconnects on transient failures and resends unacknowledged records without requiring any application-level error handling code.
Efficient Resource Management - Once data syncs successfully to Delta tables, Zerobus Ingest automatically cleans up Write Ahead Log (WAL) logs and metadata, freeing disk space for new data without manual intervention.
Schema Management - Automatic validation against your Delta table schema catches data quality issues at ingestion time, preventing malformed data from entering your Lakehouse.
Performance benchmark
Maximum throughput can be achieved when a client app and endpoint are in the same geo region.
100MB/second per stream (benchmarked with 1KB-sized messages)
15,000 rows per second per stream
Usage
Implement Zerobus
SDKs
Users will interact with Zerobus Ingest through a dedicated SDK for their language of choice. The documentation and samples are out for Python SDK, Rust SDK and Java SDK . Both the Go and TypeScript SDKs for Zerobus Ingest are now publicly available. GRPC is the main communication mechanism for Zerobus Ingest.
Databricks documentation contains a well documented guide with sample clients in multiple languages. It guides you right from installing the SDK in your preferred language to creating a Protobuf definition and a sample usage.
Supported Formats
Protocols: gRPC (primary), HTTP REST, Kafka wire format (coming soon)
Data Formats: Protocol Buffers, JSON
TIPs
Visit the table history on UC to get a sense of how frequently the table is updated
Handle the two exceptions gracefully NonRetriableException, ZerobusException.
Even though Zerobus Ingest periodically issues data file compactions, so you don’t need to worry about the small files
Don’t forget to create a table with appropriate data types before you run the client
Zerobus Ingest Deep Dive
While the experience is simple, the engineering is sophisticated!
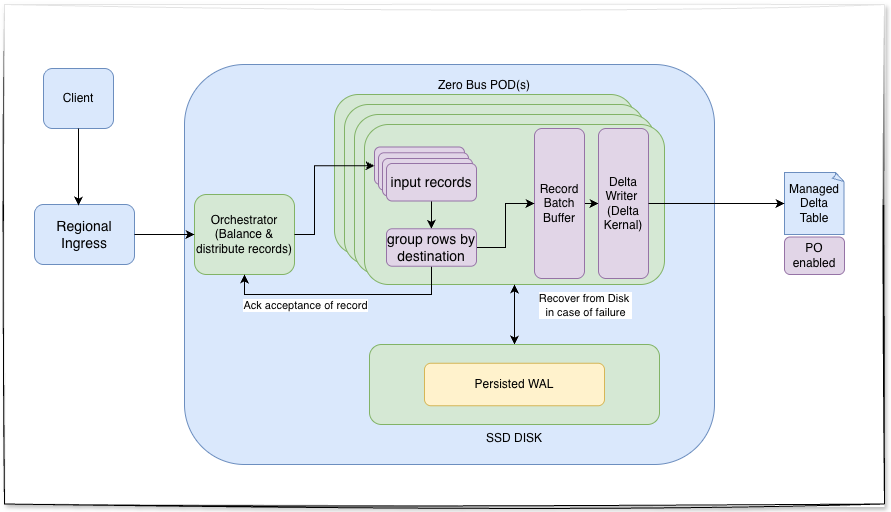
Components
Zerobus Ingest Server - Think of them as scalable stateful pod on K8s attached with an SSD disk(high IOPS). Its responsibilities include:
Schema validation of the message to the table.
Materializing the data in a timely manner to the target table.
Sending an acknowledgement to the client that the data is durable.
Smart Networking and orchestration - API proxy which distributes the streams to Zerobus Ingest servers per the target delta table and scales pods as the utilization nears the roof
Delta kernel - Record batch writer kicks off every 1-5 seconds, uses Delta kernel(uses Arrow) and writes the record batch to the delta table. Kicks in the PO compaction to avoid small files. Rust APIs hides all the complex details of the Delta protocol specification. Binding available for python.
Write-Ahead Log(WAL) - Records are immediately persisted to durable storage(think SSD disks with high IOPS) provided by the cloud platform your databricks is running on and is acknowledged in under 50ms. This guarantees durability even if something fails
Unofficial Zerobus Ingest overview
The Honest Part
Zerobus Ingest - Does not always replace the message bus
Zerobus Ingest fits direct lakehouse writes with durable acknowledgments (no bus-style retention/multi-consumer). Zerobus Ingest it not a replacement of message bus in all scenarios. If you need message bus durability/retention or multiple subscribers, Event Hubs/Kafka is likely a safer choice.
Availability
Databricks only support single availability zone (single AZ) durability. This means Zerobus Ingest service may experience downtime. This might change soon.
Kafka still wins when
Despite the cost advantages of Zerobus Ingest Ingest, Kafka remains a better choice in following scenarios:
Exactly-once semantics requirements - For financial transactions, order processing, or other workflows where duplicate processing could cause serious issues, Kafka’s exactly-once delivery guarantees are critical. While Zerobus Ingest roadmap includes this feature, organizations that need it today must still rely on Kafka.
Ultra-low latency fan-out - If your use case requires multiple consumers reading the same stream with different processing logic, Kafka’s pub-sub model excels. Zerobus Ingest currently lacks the subscriber/consumer model that makes Kafka so powerful for fan-out patterns where one stream feeds multiple downstream applications.
Other Limitations
As of writing,
Zerobus Ingest provides at-least-once delivery semantics, meaning each message will be delivered one or more times. It does not yet support exactly-once semantics. However, the duplicates can be handled using other Databricks and delta features.
Zerobus Ingest currently supports writing only to managed Delta tables
Schema evolution on target tables is not yet supported in Zerobus Ingest, so the table schema must match the incoming message structure.
Each individual message is limited to a maximum size of 10 MB when processed through Zerobus Ingest.
What’s Next
Databricks is actively enhancing Zerobus Ingest with several key features in development. The roadmap includes exactly-once delivery semantics for stronger consistency guarantees, MQTT protocol support to broaden IoT and device connectivity options, comprehensive CDC pipeline capabilities that will handle updates and deletes in addition to inserts and subscriber/consumer model to enable more flexible data consumption patterns.
Enjoy streaming in a cost efficient and simplified manner!
Conclusion
Zerobus Ingest offers a compelling alternative to message bus in a lot of scenarios. While Kafka remains essential for complex streaming architectures, Zerobus Ingest closes the gap for straightforward ingestion use cases—delivering the reliability you need at a fraction of the cost and complexity.
The cost savings extend beyond infrastructure. Kafka expertise commands premium salaries, and maintaining distributed message bus systems requires dedicated engineering time that could be spent on higher-value work. Zerobus Ingest’s simplicity means junior engineers can manage what previously required highly skilled distributed systems expertise. When you factor in reduced operational overhead, lower training costs, and faster time-to-production, the economics become even more compelling. Sometimes the best architecture isn’t the most sophisticated—it’s the one that solves your problem.