
Agents are like onions (they have layers)
Using custom scorers to investigate spans within a trace in MLflow 3+.


Agents are becoming more sophisticated. Traditionally, we use LLM judges to assess the quality of an Agent’s performance. Databricks has its own suite of pre-defined LLM scorers that can evaluate safety, correctness, etc. For RAG agents, there are scorers that can help you analyze retrieval groundedness and retrieval relevance that can help analyze the quality of the retriever (aka the Vector Search). However, when the agent has access to multiple tools, end-to-end evaluation is not sufficient.
Imagine that we have an agent with access to several tools:
A python code execution function
A retriever that gets relevant Databricks documentation
A translation function
A text summarization function
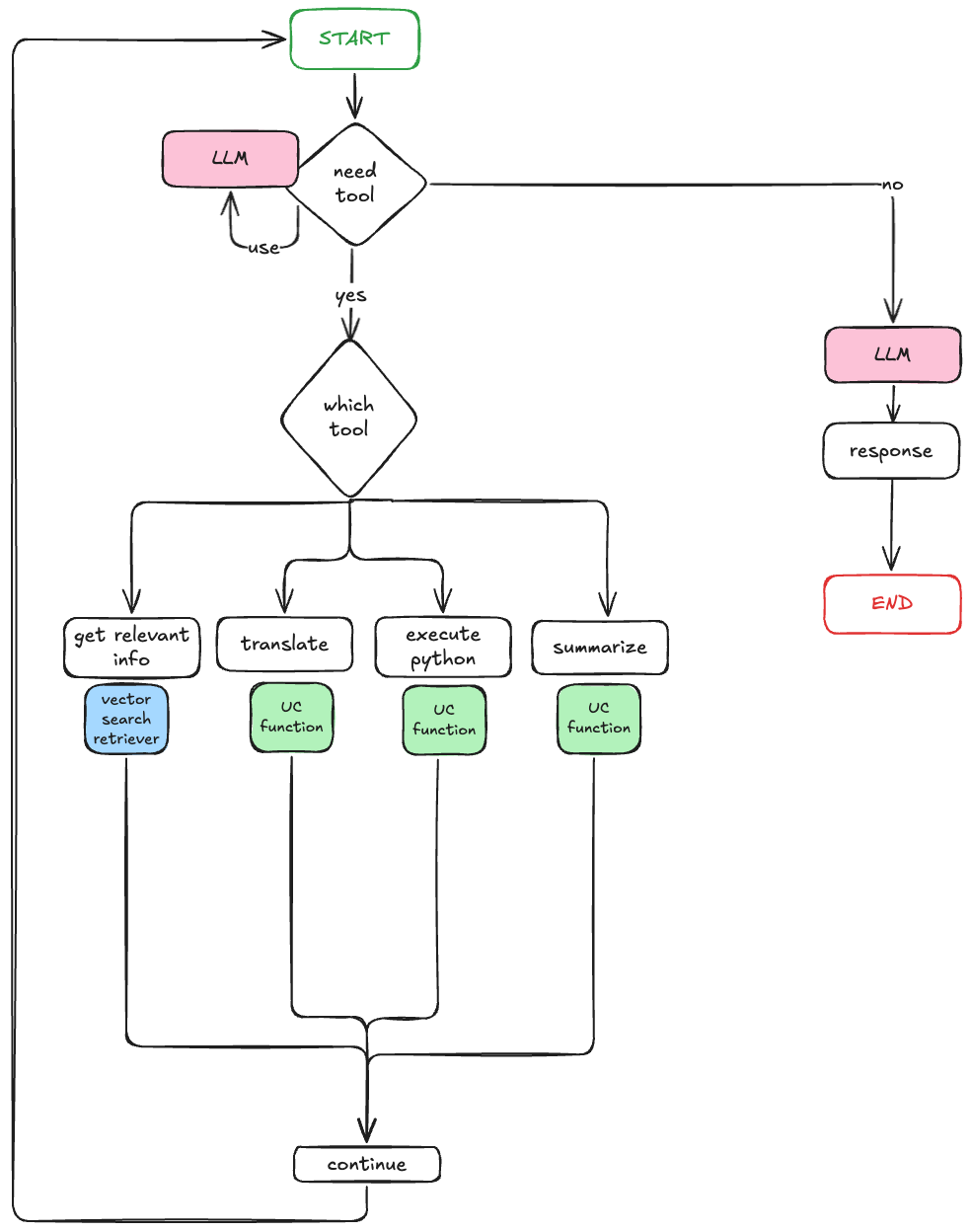
As you can see in the diagram above, there are at minimum two LLM calls-- one when the agent begins and decides what tool to use (if there is a tool to be used) and another when to aggregate the tool output. How do we know if the LLM is making smart decisions about when to use these tools and what tools to use?
Consider these examples:
Request: “What’s 2+2?”
The agent should not use any tools, since this is quite simple math.
Request: “What would print(f”Random string {variable}”) output in Python?”
The agent should use the execute python function.
Request: “How do I create a Databricks cluster?”
The agent should use the retriever to get relevant docs.
With MLflow, we can generate traces easily. In the example agent I am using here, I use langgraph and declare mlflow.langchain.autolog() to automatically trace every call in the app. Standard MLflow scorers would evaluate the final response quality, but they could miss whether the agent made smart tool choices. Custom scorers offer some flexibility here-- we can define one to break a trace down into its spans, independently analyzing each tool call.
How do we implement a custom scorer?
There are two main ways of implementing a custom scorer: (1) using the @scorer decorator for a python function or (2) using the Scorer class for more complex scorers that require state. In our example here, we are using the Scorer class and overriding the __call__ method.
All scorers retrieve the same inputs:
def __call__(
self,
*,
inputs: Optional[dict[str, Any]],
outputs: Optional[Any],
expectations: Optional[dict[str, Any]],
trace: Optional[mlflow.entities.Trace]
) -> Feedback:First, we are going to determine the required tools. For each user input, the scorer uses an LLM judge to determine which tools should be required. MLflow offers two options for creating a judge: prompt based judges and guideline judges. Prompt based judges, using the custom_prompt_judge function, allows to define custom categories (rather than pass/fail binaries) and have full prompt control.
Here, we are using a custom prompt and mapping our outputs (required and not required) to numeric values, which can be aggregated later on.
from mlflow.genai.judges import custom_prompt_judge
def determine_required_tools(self, user_input: str, tools: Dict[str, str]) -> Dict[str, bool]:
required_tools = {}
for tool_name, tool_description in tools.items():
judge = custom_prompt_judge(
name=f"{tool_name}_requirement_judge",
prompt_template=tool_requirement_prompt,
numeric_values={"required": 1.0, "not_required": 0.0}
)
result = judge(
inputs=user_input,
tool_name=tool_name,
tool_description=tool_description
)
required_tools[tool_name] = result.value == 1.0
return required_tools
Second, we are going to extract the actual behavior from the trace spans. MLflow automatically captures every tool call as a span with SpanType.TOOL. Our scorer searches through each span to get the tool name, tool response, and the tool status.
def extract_used_tools_from_trace(self, trace: mlflow.entities.Trace) -> List[Dict[str, Any]]:
tools = []
spans = trace.search_spans(span_type=SpanType.TOOL)
for span in spans:
messages = span.get_attribute(SpanAttributeKey.OUTPUTS)
content = json.loads(messages['content'])
t = {"tool_call_id": messages['tool_call_id'],
"tool_name": messages['name'],
"tool_response": content['value'],
"tool_status": messages['status']}
tools.append(t)
return toolThis gives us more visibility into the agent’s decision-making process. Now that we have what tools were actually used, we can score this against what should have happened.
def compare_tool_usage(self, required_tools: Dict[str, bool], used_tools: List[Dict[str, Any]]) -> Dict[str, Any]:
required_tools = [name for name, required in required_tools.items() if required]
correctly_used_tools = []
failed_required_tools = []
incorrectly_used_tools = []
for tool in used_tools:
if tool['tool_name'] in required_tools:
correctly_used_tools.append(tool)
required_tools.remove(tool['tool_name'])
# Custom logic to determine if tool execution was successful
response = self.interpret_tool_call_response(tool['tool_name'], tool['tool_response'], tool['tool_status'])
if response != "success":
failed_required_tools.append(tool)
else:
incorrectly_used_tools.append(tool)
return {
"correctly_used_tools": correctly_used_tools, # used and required ! :)
"incorrectly_used_tools": incorrectly_used_tools, # used but not required
"failed_required_tools": failed_required_tools, # required but response was not successful
"missing_required_tools": required_tools # required but not used
}Finally, we can compute the score based on the number of mistakes that the LLM made. The output of the Scorer should be a Feedback object. We can add rationale here as well, so when the scorer is used on new traces, we can look at the rationale directly in the MLflow Tracing UI.
The value of the Feedback object can be anything. Here we defined it as a simple Boolean, but it can be a Float, Int, String, a List, or a Dict. Again, lots of flexibility in how you define the LLM Scorers!
return Feedback(
value=True,
rationale="Used required tools properly. No feedback needed.",
source=AssessmentSource(source_type="LLM_JUDGE", source_id="tool_usage_scorer")
)
else:
return Feedback(
value=False,
rationale="Incorrectly used tools. Check metadata for more information. ",
source=AssessmentSource(source_type="LLM_JUDGE", source_id="tool_usage_scorer")
)You can finally use the scorer in your evaluation workflow.
Key Takeaways
By implementing custom scorers that analyze the spans within a trace, you can catch inappropriate LLM tool calls and usage and identify unnecessary tool usage. In order to use a custom scorer in MLflow:
Define your evaluation criteria (what is good tool usage for your use case? Do you always want to be relying on tools?)
Create the custom scorer class
Integrate easily with the evaluation pipeline via mlflow.genai.evaluate()
Practically, start tracking one or two critical tools rather than trying to evaluate everything all at once. In this example, I count every single mistake, but define what ‘too many mistakes’ means in your use case. In your use case, you may not want to add everything except the failed tools and missing required tools.
Custom MLflow scorers give you the control to build more reliable agents. Take a look at the full code implementation here.
Happy scoring!